
Bloom's AI Collaboration Framework — v2
A cognitive model for human–AI partnership. v2 reframes the L3/L4 line as an auditability boundary — and tells the truth about Level 1.

Jasem Neaimi
AI Collaboration Researcher
In 1956, Bloom's Taxonomy named six levels of cognitive work — Remember, Understand, Apply, Analyze, Evaluate, Create. Anderson and Krathwohl revised it in 2001. I built on that revision to ask a different question: not what kind of thinking is this, but who should lead at each level — and why.
v1 of the framework (March 2026) called the line between L3 and L4 a "trust boundary." After 25 real Claude Code sessions across 40 days — bilingual frameworks, shipped architecture, embedded product features — that name turned out to be wrong. v2 fixes it.
The split cognitive stack
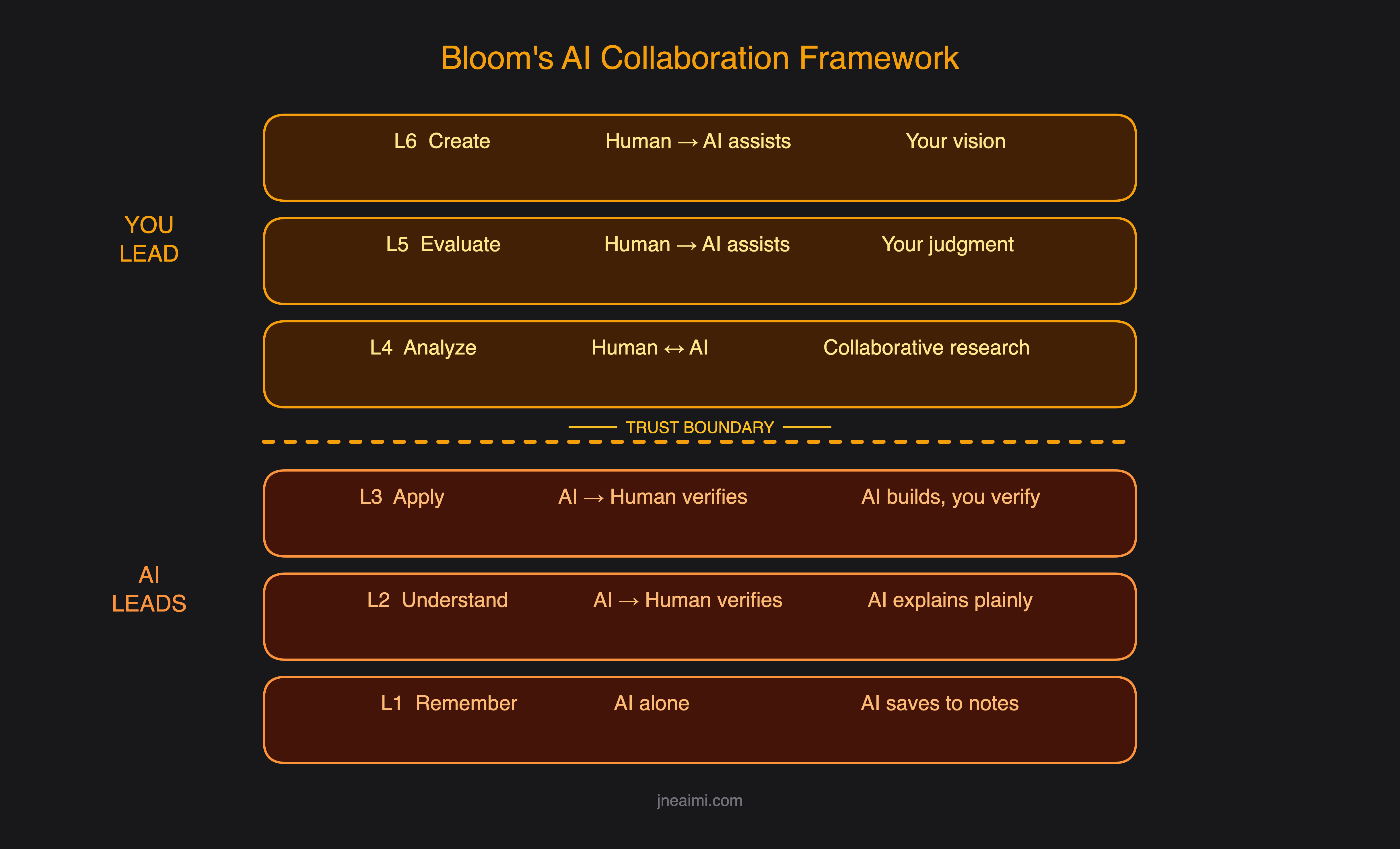
The auditability principle (the v2 reframe)
The line at L3/L4 is not about trusting AI. It is about whether an external referent exists.
- Below the line (L1–L3): an external referent exists — a source, a document, a runtime, the spec the human just produced. AI output is checkable against that referent.
- Above the line (L4–L6): no referent exists outside the human's head. The ground truth is the human's context, values, and judgment. There is nothing else to check the output against.
This single move fixes a structural problem v1 carried. v1 said L1 was "AI alone — infinite-recall machine that never forgets." That was the most damaging sentence in the document. AI hallucinates most confidently at L1. L1 is safe below the line not because the model is reliable, but because the source exists — a hallucinated L1 claim is falsifiable against the source. That falsifiability is what auditability means.
Practical consequence: grounding earns L1–L3 their position. An ungrounded L1 claim ("UAE MOUs are binding by default") with no citation is functionally an L5 claim — it depends on the AI's authority instead of a checkable source. Always require sources at L1–L3 for anything you'll act on.
The line is not fixed
v1 drew the line at L3/L4 and treated it as a law. v2 treats it as a starting position that contracts as stakes rise.
| Condition | Effect on the line |
|---|---|
| Consequences grow | Line moves up — more verification required |
| Domain is novel to AI | Line moves up — fewer trained patterns |
| Verification is expensive | Line moves up — referent harder to check |
| Task is reversible | Line moves down — can be undone |
| Human has domain expertise | Line moves down — audit is cheap |
| Stakes are low | Line moves down — error is recoverable |
Heuristic: "If this output is wrong and I rely on it, what breaks?" The answer tells you where the line sits today, for this task.
The 6+3 universal questions
The questions belong to you. AI cannot answer them — it does not know your context, stakes, or values. v2 expands the set from 6 to 9, in three rounds.
Round 1 — Purpose, Resources, Success
- What is the purpose?
- What does each side bring?
- What does success look like?
Round 2 — Risk, Scope, Commitment (mandatory in deep mode)
- What am I afraid of?
- What's the scope?
- How deep am I going?
Round 3 — Epistemics (mandatory for heavy commitment)
- What am I assuming?
- Is this decision reversible?
- What would change my mind?
Round 3 is the v2 addition. Question 9 is the load-bearing one — if you can't name what would change your mind, you are not evaluating, you are rationalizing. Round 3 catches motivated reasoning before it becomes an L3 artifact.
The L4↔L5 spiral — mechanically guaranteed
v1 described the spiral as something that "naturally" emerged. Across 25 real sessions, it appeared in exactly one. The other 24 ran linear. v2 makes the spiral mechanical: at least one L4→L5 loop-back is required before producing the L3 deliverable.
The reason is structural. The 6+3 questions get answered before L4 analysis — which means they get answered without the information L4 surfaces. Analysis almost always reveals something the human didn't know at the start. That new information frequently changes a Round 1 or Round 2 answer. Skip the loop-back, and the L3 output is built against a stale spec.
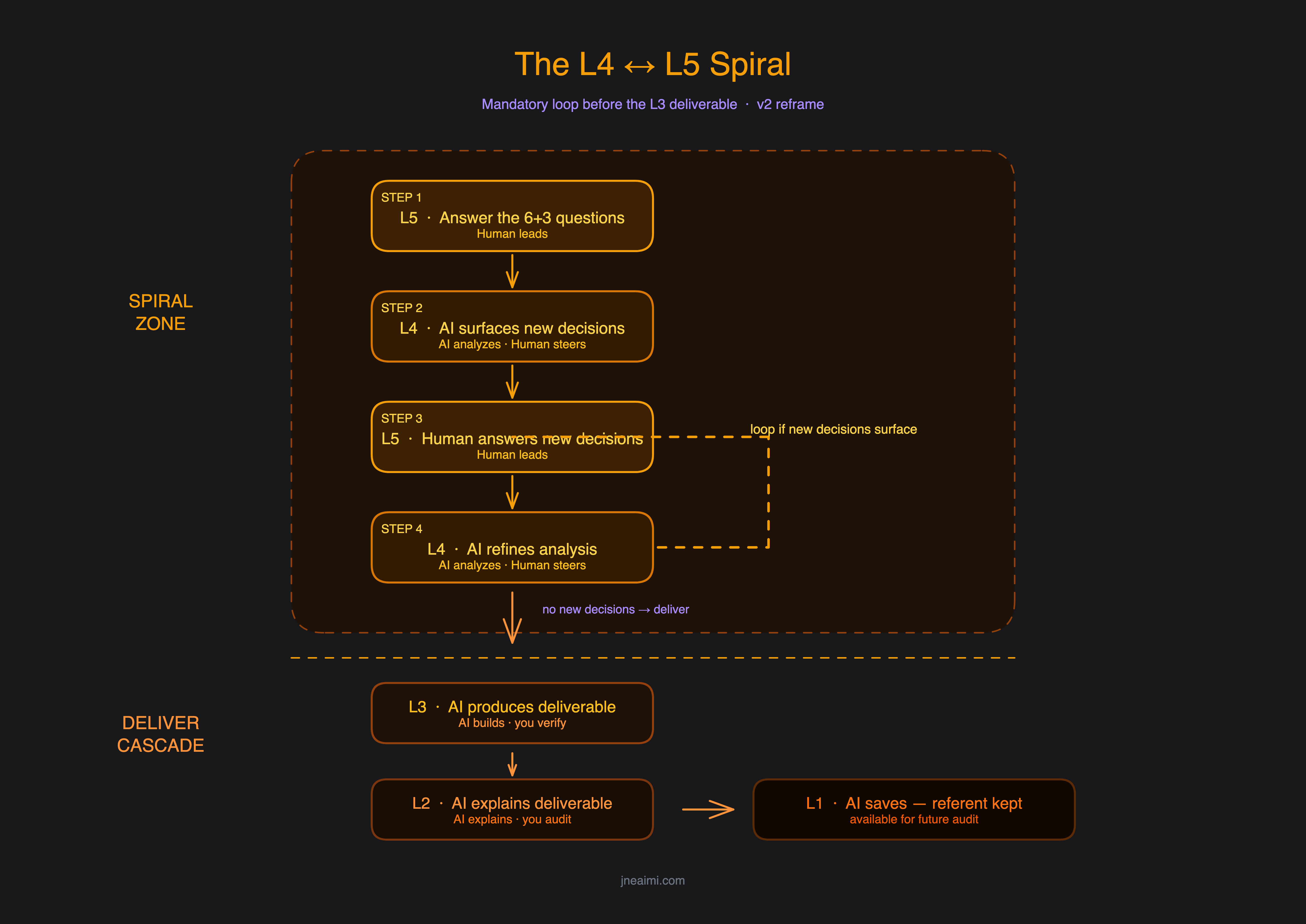
Quick mode and deep mode
v1 had one mode. v2 has two — because applying the full protocol to "should I respond to this Slack message" wastes 40 minutes on a question that warranted five.
Quick mode — Round 1 only (3 questions: Purpose, Success, Scope). No L4 research. No mandatory save. Use it for personal-pillar daily decisions, low stakes, reversible.
Deep mode — Full 6+3 questions, mandatory L4↔L5 loop, mandatory L3 deliverable, mandatory L2 explanation, mandatory L1 save. Use it when someone else will rely on the output, the output is hard to reverse, the domain requires expertise you don't have, or significant time/money is at stake.
Default to deep mode whenever any of those conditions is true.
The 9 life pillars
v1 used 10 flat domains (legal, product, code, content…). It worked, but the list was arbitrary. v2 reframes around 9 life pillars — same skeleton, pillar-tuned framing. The framework adapts to any pillar, not just work and code.
| Pillar | What it covers |
|---|---|
| Work / Craft | Building, coding, shipping, professional output |
| Decisions | Between options, go/no-go, prioritization |
| Money | Spending, investing, pricing, deals |
| Health | Sleep, fitness, eating, mental load, medical |
| Relationships | Partner, family, friends, professional connections |
| Learning | New skills, deep dives, deliberate practice |
| Identity / Direction | Values, long bets, who you want to be |
| Time / Energy | Calendars, routines, priorities, what to drop |
| Faith / Meaning | Values, principles, what matters |
Honest disclosure: across 25 observed sessions, 88% landed in Work/Craft. Six pillars have zero usage so far. The framework's pillar taxonomy is currently aspirational on those six — that gap is the work in front of v3.
Failure modes
Naming how the framework breaks reduces recurrence. Seven patterns recur:
- Semantic audit without expertise. The format looks right, the substance is wrong, the human cannot tell. Mitigation: identify high-stakes audit needs at Round 2 Q4; budget for expert review.
- Ungrounded L1 taken as fact. AI claims something at L1 with no source; the human treats it as verified because L1 is "below the line." Mitigation: always require sources for L1 claims you'll act on.
- Round 1 answered superficially. The first answer that comes to mind, not the most accurate one. The L3 deliverable inherits the inaccuracy. Mitigation: Round 3 epistemic prompts.
- L4 skipped because the L3 looks good. A polished draft hides the missing research. Mitigation: mandatory in deep mode — do not skip.
- Downstream agents drift from the saved decision. /think makes a decision; the developer agent never reads it; the implementation diverges. Mitigation: L1 save is mandatory in deep mode, and the path must be findable.
- Framework applied to a question that didn't earn it. Quick mode exists for this reason.
- Auto-fire without transparency. Across observed sessions, 40% of /think invocations were auto-fired by Claude — context matched, the protocol activated, the user wasn't told. Mitigation: the assistant must announce auto-fires on the first turn so the user can opt out. The human leads at L5 — including the meta-decision to engage the framework at all.
Worked example — UAE Partnership MOU
Domain: Legal. Commitment: Heavy (binding, multi-party, financial). Human expertise: Zero UAE contract law.
| Step | Level | Who led | What happened |
|---|---|---|---|
| 1 | 5. Evaluate | Human | Round 1+2: purpose (win client contract), contributions (market access vs. training expertise), success criteria, fears, scope, commitment level |
| 2 | 4. Analyze | AI ↔ Human | AI researched UAE MOU law. Key finding: MOUs are binding by default in UAE — opposite of Western jurisdictions. Three new decisions surfaced. |
| 3 | 5. Evaluate | Human | Decided: subcontract model, penalty structure, exclusivity, confidentiality |
| 4 | 4. Analyze | AI | Further research on penalty enforceability, arbitration practice (DIAC/ADCCAC), Schedule A pattern |
| 5 | 5. Evaluate | Human | Final decisions on revenue split, penalty percentages, delivery model |
| 6 | 3. Apply | AI | Drafted full 14-clause MOU |
| 7 | 2. Understand | AI | Plain-language explainer for every clause — what it does, why it's there, what the human is committing to |
| 8 | 1. Remember | AI | Saved to Second Brain with sources |
Five L4↔L5 loops, not one. The human entered with no domain knowledge and walked out with both a deliverable and enough understanding to take it to a UAE-qualified lawyer with informed questions.
Honest caveat: the framework produced a strong first draft and a thorough explainer. It did not replace legal review. For binding contracts, medical decisions, or financial commitments, the framework is a learning accelerator and drafting aid — not a substitute for domain expertise on high-stakes semantic audits.
Where to go next
/thinkskill — install in 2 minutes — the operational protocol as a Claude Code skill.- Top-Down Learning with Bloom's Taxonomy — the cognitive science behind starting at L5.
- Evaluate Before You Build — the tactical pre-build checkpoint for code.
- Print-grade v2 PDF — the canonical 14-section document.
- Repo on GitHub — full framework, skill, pillar taxonomy, worked examples. MIT-licensed.
AI should make us sharper thinkers, not lazier ones. v2 is the version that earns that line.
Get new insights
Subscribe for the latest research and frameworks, delivered to your inbox.